
The New York Times es uno de los periódicos que mejor trabaja su muro de pago, en parte por el tiempo que lleva aprendiendo sobre su rendimiento y mejorándolo, ya que el periódico neoyorquino puso en marcha el sistema hace ya más de 10 años, en concreto en marzo de 2011. La tecnología, en este caso, a diferencia de otros medios, sí está siendo diferencial para que el rendimiento sea tan positivo.
Rohit Supekar, científico de datos en el equipo de objetivos algorítmicos de The New York Times, que trabaja en el desarrollo y la implementación de modelos de aprendizaje automático causales para potenciar el muro de pago de The Times, ha desvelado algunas claves interesantes de cómo el periódico usa el aprendizaje automático para hacer que su muro de pago sea más inteligente.
Desde su inicio, el muro «medido» fue diseñado para que los no suscriptores pudieran leer una cantidad fija de artículos cada mes antes de encontrarse con el muro de pago.
Esta estrategia, en el concreto caso de The New York Times (y no trasladable en absoluto a muchos otros medios) ha demostrado ser exitosa en la generación de suscripciones y, al mismo tiempo, permite el acceso exploratorio inicial a nuevos lectores.
Cuando se lanzó el muro de pago, el límite de noticias que un lector no suscriptor podía leer era el mismo para todos los usuarios. Sin embargo, ahora están utilizando con éxito un modelo de aprendizaje automático causal llamado Dynamic Meter (medidor dinámico) para fijar esa cantidad de artículos que se pueden leer de manera personalizada y hacer que el muro de pago sea más inteligente.
La estrategia de muro de pago del periódico gira en torno al concepto del embudo de suscripción.
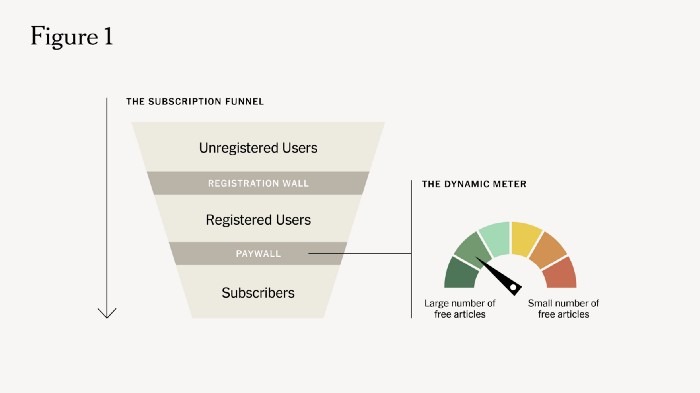
En la parte superior del embudo se encuentran los usuarios no registrados que aún no tienen una cuenta en The Times. Una vez que alcanzan el límite de lectura de artículos como no registrados, se les muestra un muro de registro que bloquea el acceso y se les pide que creen una cuenta, o que inicien sesión si ya tienen una cuenta.
Hacer esto les da acceso a más contenido gratuito y, dado que su actividad ahora está vinculada a su identificación de registro, permite comprender mejor su necesidad actual por el contenido de Times.
«Esta información del usuario es valiosa para cualquier aplicación de aprendizaje automático y también alimenta el medidor dinámico», explica Supekar.
El modelo de Medidor Dinámico desempeña un doble papel. Trata por un lado de «respaldar nuestra misión de ayudar a las personas a comprender el mundo», dice Supekar, y por otro de conseguir el objetivo comercial de adquirir suscripciones. Es decir, que los lectores registrados lean lo máximo posible pero que, al mismo tiempo, desemboque en suscripciones de pago en el mayor número posible. La búsqueda de ese punto óptimo de equilibrio.
Las dos métricas con las que trabaja el equipo de datos encargado del muro de pago
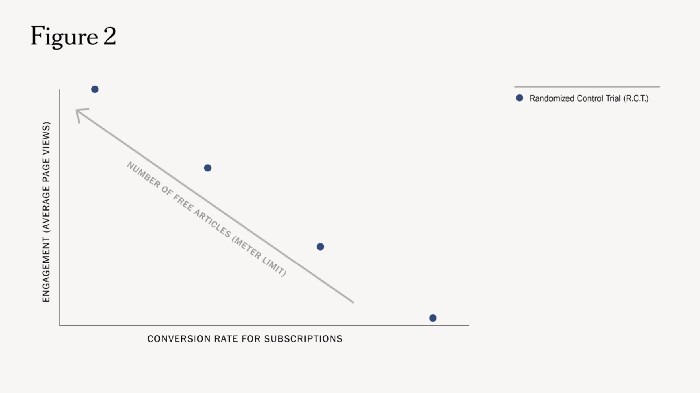
El sistema de The NYT optimiza para ello dos métricas simultáneamente: el compromiso que los usuarios registrados tienen con el contenido del Times y la cantidad de suscripciones que genera el muro de pago en un período de tiempo determinado.
Estas dos métricas tienen una relación directa inherente A vs B:
A) A medida que aumenta el límite de artículos libres para los usuarios registrados, aumenta la participación medida por el número promedio de visitas a la página. En este caso, este incremento del número de artículos en abierto va acompañado de una reducción en la tasa de conversión de las suscripciones, en gran parte porque hay un número menor de usuarios registrados que se encuentran con el muro de pago.
B) Por el contrario, una mayor cantidad de veces que salta el muro de pago debido a límites de medición más estrictos afecta la habituación de los lectores y potencialmente hace que se interesen menos en el contenido. Esto, a su vez, afecta el potencial para convertirlos en suscriptores a largo plazo.
En esencia, el medidor dinámico debe optimizar la conversión y el compromiso al tiempo que equilibra una compensación entre ellos.
El objetivo del modelo es, por lo tanto, establecer límites en cuanto a número de artículos que pueden leer en abierto los suscriptores no de pago, pero registrados, a partir de un conjunto limitado de opciones disponibles.
Por lo tanto, el modelo realiza una acción que afectará el comportamiento de un usuario e influirá en el resultado, como su propensión a suscribirse y su compromiso con el contenido de Times.
Ahí entra en funcionamiento el modelo predictivo de aprendizaje automático que usa datos de otros usuarios para determinar lo que habría sucedido y actuar en consecuencia.
¿Cómo funciona técnicamente el modelo?
El equipo de datos de The NYT entrena dos modelos de aprendizaje automático a los que llama «aprendices de base». Las funciones se determinan exclusivamente a partir de datos propios sobre su interacción con el contenido del Times.
Usando los datos, ajustan esos dos modelos de aprendizaje automático, que predicen la propensión a la suscripción y la participación, respectivamente. Para maximizar estos dos objetivos simultáneamente, los convierten en un solo objetivo, que detalla el número de artículos que en cada caso un lector puede leer para maximizar su vinculación con el contenido del periódico.
Una explicación técnica detallada del proceso puede encontrarse en el artículo original de Rohit Supekar.
