

Comprender las preferencias de los lectores de un medio de comunicación es fundamental para mejorar la experiencia del usuario y potenciar su compromiso con los productos informativos. Tener indicadores precisos que muestren qué área es cada vez más importante puede ayudar a los periodistas a enfocarse en temas de interés y tendencias.
La predicción de tendencias en los medios se desarrolla a través de un modelo de ciencia de datos creado mediante el aprendizaje automático y el análisis de series de tiempo.
Uno de los medios que ha afinado su modelo para predecir tendencias es el Financial Times.
Análisis de datos y desviaciones sobre series de tiempo
Los flujos de datos propios de los que dispone el FT contienen información que permite una retroalimentación inmediata de aquello sobre lo que las personas prestan atención actualmente y cómo se sienten sobre ciertos temas.
“Estas tendencias -indica Adam Gajtkowski, científico de datos del Financial Times- pueden experimentar aumentos repentinos por incremento de interés de los lectores. Suelen corresponder a eventos del mundo real como temas de salud, incidentes y movimientos políticos. El conocimiento de los temas que empiezan a ser tendencia permite a la redacción anticiparse a las necesidades cambiantes de información de los usuarios y tomar decisiones sobre dónde asignar los recursos”.
Estas tendencias se observan sobre series de tiempo, que permiten ver “señales”. Se define “señal” como cualquier desviación del patrón histórico de esas series de tiempo. Para detectar señales en series de tiempo, el FT utiliza varios conjuntos de datos internos, que tiene unas ventajas (fácil acceso, costes marginales pequeños, conjunto de datos limpio e información de alta calidad sobre la actividad de los lectores), pero no incluye “señales” externas sobre tendencias de lectura más amplias, como tendencias en motores de búsqueda / redes sociales, pero sí los datos internos que hagan referencia a motores de búsqueda o redes sociales, es decir, cómo llega la gente a FT, qué se retuitea más o desde qué noticias de RRSS llegan, etc.”.
“Sin embargo, en general, -indica Gajtkowski- creemos que predecir tendencias utilizando datos internos aún nos ayudará a retener a los usuarios existentes, ya que la parte editorial tendrá la información para invertir en historias más relevantes para los usuarios”.
La ejecución del modelo principal se puede resumir en 5 pasos:
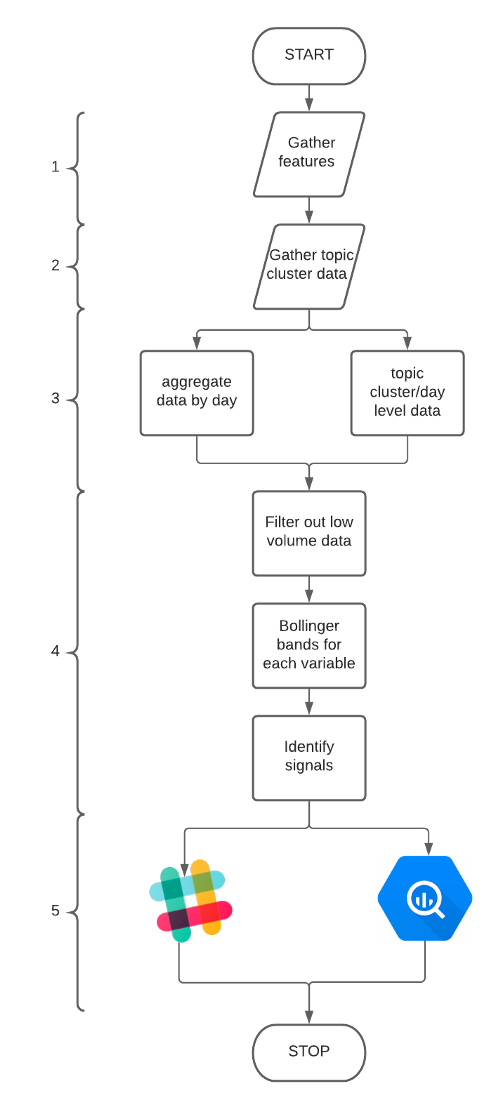
- Reunir características.
- Asignar los artículos a grupos de temas definidos por aprendizaje automático no supervisado y Procesamiento de Lenguaje Natural (PNL).
- Recopilar características en dos conjuntos de datos, uno a nivel de día y otro a nivel de grupo de día/tema.
- Derivar Bandas de Bollinger (como la que se usan para mercado algorítmico financiero, y que en este caso muestran el grado de certeza de que un valor dado se ubicará entre estas bandas o fuera de ellas); detectar señales de forma M / L, y marcar estas señales. Por ejemplo, si se han dibujado Bandas de Bollinger con un parámetro de dos desviaciones estándar del promedio móvil simple de 5 días, significa que esperaríamos que el 95% de nuestros datos cayeran dentro de estas bandas (dado que nuestros datos se distribuyen normalmente).
- Mostrar datos a las partes interesadas mediante Slack.
Miles de puntos de datos escaneados a diario
Este modelo del Financial Times escanea miles de puntos de datos todos los días, tomando como referencia esas fuentes internas. “Recopilamos páginas vistas de referencia de varias plataformas de redes sociales, motores de búsqueda, nuevas suscripciones, personas que interactúan con las secciones de comentarios y muchos más. También desglosamos parte de este tráfico por grupos de temas que se derivaron mediante el aprendizaje automático no supervisado y el PNL”.
Luego, el modelo busca una forma de M o señales en forma de L invertida en la serie de tiempo que identifican valores atípicos consistentes. A estos valores atípicos es a lo que se llama ‘señales’.
Una vez que se identifica la señal para un conjunto de datos dado, los científicos de datos del FT la marcan y la muestran a las partes interesadas en forma de gráficos y texto.
El modelo no hace sugerencias directas. Simplemente automatiza la detección de señales y muestra estas señales a las partes interesadas. Luego, los periodistas pueden verificar el gráfico, decidir si la señal es relevante e investigar la historia por su cuenta.
Los interesados en el backtesting, parte técnica y de programación pueden ampliar información en este enlace





 se suma a la red latinoamericana que entrena a los futuros periodistas para lidiar con la desinformación")









 se alza con el premio al mejor sitio web europeo de noticias de WAN-IFRA")








: “Entiende tu mente” entra directamente al segundo puesto")

